41 keras reuters dataset labels
keras source: R/datasets.R The `dataset_reuters_word_index()` #' function returns a list where the names are words and the values are #' integer. e.g. `word_index[["giraffe"]]` might return `1234`. #' #' @family datasets #' #' @export dataset_reuters <-function (path = "reuters.npz", num_words = NULL, skip_top = 0L, maxlen = NULL, test_split = 0.2, seed = 113L, start ... The Reuters Dataset - Martin Thoma The Reuters Dataset · Martin Thoma The Reuters Dataset Reuters is a benchmark dataset for document classification . To be more precise, it is a multi-class (e.g. there are multiple classes), multi-label (e.g. each document can belong to many classes) dataset. It has 90 classes, 7769 training documents and 3019 testing documents .
Tutorial On Keras Tokenizer For Text Classification in NLP To do this we will make use of the Reuters data set that can be directly imported from the Keras library or can be downloaded from Kaggle. This data set contains 11,228 newswires from Reuters having 46 topics as labels. We will make use of different modes present in Keras tokenizer and will build deep neural networks for classification.
Keras reuters dataset labels
Datasets - keras-contrib IMDB Movie reviews sentiment classification. Dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a sequence of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data. Text Classification in Keras (Part 1) — A Simple Reuters ... The Code import keras from keras.datasets import reuters Using TensorFlow backend. (x_train, y_train), (x_test, y_test) = reuters.load_data (num_words=None, test_split=0.2) word_index = reuters.get_word_index (path="reuters_word_index.json") print ('# of Training Samples: {}'.format (len (x_train))) › api_docs › pythonModule: tf.keras.layers.experimental.preprocessing ... Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly
Keras reuters dataset labels. Multiclass Classification and Information Bottleneck — An ... The Labels for this problem include 46 different classes. The labels are represented as integers in the range 1 to 46. To vectorize the labels, we could either, Cast the labels as integer tensors One-Hot encode the label data We will go ahead with One-Hot Encoding of the label data. This will give us tensors, whose second axis has 46 dimensions. Introduction to Keras, Part One: Data Loading | by Samhita ... Data labels is a 1D array specifying a label against every image. Using matplotlib library, you can show the images present in the dataset. Output Image by Author Image Generator An Image Generator class can be used to specify certain traits to the images in a dataset. Using the data_dir which you generated in section 2.2. Classifying Reuters Newswire Topics with Recurrent Neural ... The dataset is available in the Keras database. It consists of 11,228 newswires from Reuters along with labels for over 46 topics. Method and Results: Datasets in Keras - GeeksforGeeks Keras is a python library which is widely used for training deep learning models. One of the common problems in deep learning is finding the proper dataset for developing models. In this article, we will see the list of popular datasets which are already incorporated in the keras.datasets module. MNIST (Classification of 10 digits):
TensorFlow - tf.keras.datasets.reuters.load_data - Loads ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers). Keras Datasets | What is keras datasets? | classification ... Reuters classification dataset for newswire is somewhat like IMDB sentiment dataset irrespective of the fact Reuters dataset interacts with the newswire. It can consider dataset up to 11,228 newswires from Reuters with labels up to 46 topics. It also works in parsing and processing format. # Fashion MNIST dataset (alternative to MNIST) › api_docs › pythonModule: tf.keras.layers.experimental.preprocessing ... Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly Text Classification in Keras (Part 1) — A Simple Reuters ... The Code import keras from keras.datasets import reuters Using TensorFlow backend. (x_train, y_train), (x_test, y_test) = reuters.load_data (num_words=None, test_split=0.2) word_index = reuters.get_word_index (path="reuters_word_index.json") print ('# of Training Samples: {}'.format (len (x_train)))
Datasets - keras-contrib IMDB Movie reviews sentiment classification. Dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a sequence of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data.
Best Guide of Keras Functional API - Eduonix Blog


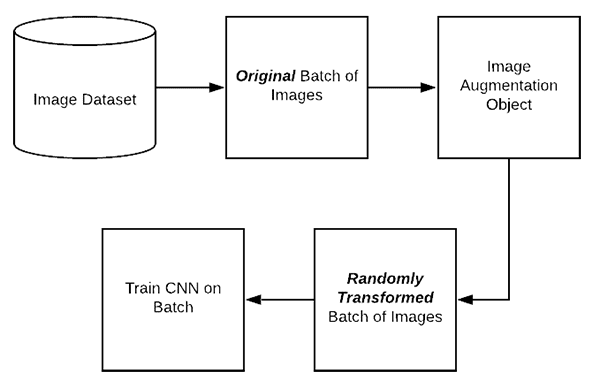
Data enhancement --Keras Image Data Augmentation various arguments detailed - Programmer Sought
Handling images deftly using Keras’ Image Data Generator | by Pooja Ravi | SRM MIC | Oct, 2020 ...

Keras text preprocessing and image preprocessing - DWBI Technologies
GitHub - ch-tseng/data-augmentation-Keras
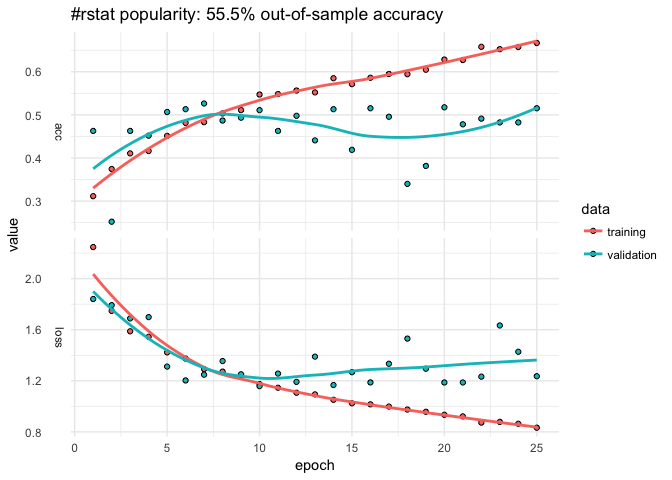
RStudio AI Blog: Analyzing rtweet Data with kerasformula

Custom Data Augmentation in Keras

Post a Comment for "41 keras reuters dataset labels"